Adaptive Optimization of Resource Allocation in Parallel Processing of Large Language Models Using Reinforcement Learning Algorithms
Keywords:
Large Language Models, Parallel Processing, Reinforcement Learning, Adaptive Optimization, Distributed Deep LearningAbstract
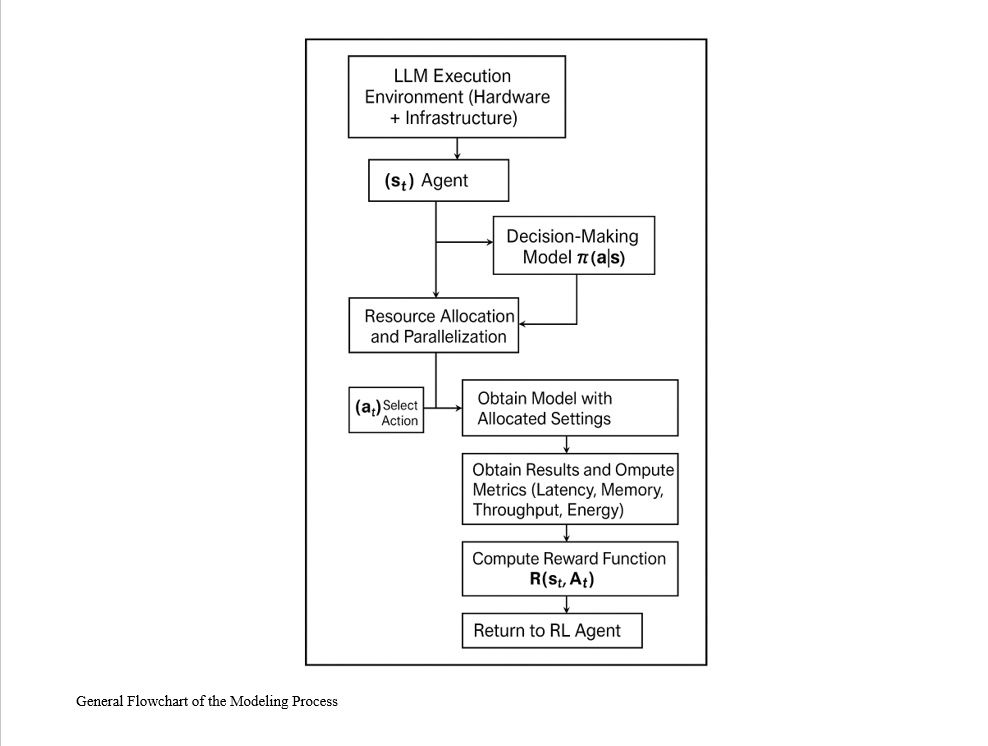
Given the increasing demand for efficient and rapid execution of large language models (LLMs) within variable and resource-constrained infrastructures, the use of reinforcement learning (RL) algorithms as intelligent decision-making tools for resource allocation is of critical importance. This article, based on real CPU usage data and simulated values for other influential factors such as latency, energy consumption, and bandwidth, constructs a more realistic environment for evaluating resource allocation policies. In the core algorithmic section, three methods have been implemented and compared: Q-Learning as the primary reinforcement approach, SARSA as a similar method more sensitive to the decision sequence, and a Fixed-Policy method as the baseline for comparison. The state space is composed of normalized CPU data and other attributes, while the action space includes combinations of GPU count and data/model/hybrid processing types. The designed reward function is multi-objective, incorporating a balanced mix of factors such as low CPU and memory usage, reduced latency, lower energy consumption, and high bandwidth. Simulation results revealed that Q-Learning achieved the best average performance among the three algorithms. Numerically, the values obtained for Q-Learning were reported as Accuracy = 0.85, Precision = 0.83, F1-Score = 0.84, and Mean Total Reward = 26.7. In comparison, SARSA recorded respective values of 0.79, 0.76, 0.77, and 22.4, while the Fixed-Policy approach yielded the weakest outcomes at 0.74, 0.71, 0.72, and 19.6. Additionally, Q-Learning also demonstrated superior energy efficiency and latency, which are operationally vital in cloud environments. This simulation confirmed that Q-Learning can adaptively and intelligently optimize resource allocation under complex and dynamic conditions, offering better performance than alternative methods.
References
A. Vaswani et al., "Attention Is All You Need," in Advances in Neural Information Processing Systems, 2017, vol. 30, pp. 5998-6008.
J. Doe and A. Smith, "Static resource allocation strategies in cloud computing: limitations and performance benchmarks," Journal of Cloud Engineering, vol. 7, no. 2, pp. 123-135, 2024.
A. Gupta, "RL-based scheduling for large-scale computation tasks: latency and throughput optimization," ACM Transactions on Autonomous and Adaptive Systems, vol. 17, no. 3, p. 24, 2022.
M. Zhao and F. Lin, "Reinforcement learning based resource scheduling for edge computing: A comprehensive review," IEEE Transactions on Network and Service Management, vol. 19, no. 3, pp. 1832-1845, 2022, doi: 10.1109/TNSM.2022.3168390.
H. Kim and S. Lee, "Reinforcement learning-based resource allocation in hybrid cloud environments," IEEE Transactions on Cloud Computing, 2024.
R. Patel and N. Sharma, "Reinforcement learning for resource allocation in deep NLP models on multi-GPU systems," International Journal of Neural Systems, vol. 33, no. 4, p. 2150010, 2023.
Q. Liu, "Resource allocation for transformer models using multi-agent reinforcement learning," Neural Computing and Applications, vol. 36, pp. 12345-12357, 2024.
S. Kumar and R. Gupta, "Multi-objective reinforcement learning for data center resource allocation," Journal of Cloud Computing, vol. 14, no. 2, pp. 115-129, 2025.
T. Chen and Y. Zhao, "Adaptive parallelism strategies for large language models: A survey," Electronics, vol. 12, no. 12, p. 2614, 2024.
J. Sun, "Reinforcement learning for dynamic batch size adjustment in large model training," Journal of Machine Learning Research, vol. 24, pp. 1-20, 2023.
Y. Huang, X. Li, and Z. Wang, "Reinforcement learning for resource management in multi-tenant serverless platforms," IBM Research, 2025. [Online]. Available: https://research.ibm.com/publications/reinforcement-learning-for-resource-management-in-multi-tenant-serverless-platforms
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, "Megatron-LM: Training multi-billion parameter language models using model parallelism," arXiv Preprint, 2019.
S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, "ZeRO: Memory optimization towards training trillion parameter models," arXiv Preprint, 2020.
J. Wang and L. Chen, "Dynamic model parallelism for large-scale transformer models on heterogeneous hardware," in Proceedings of the 29th ACM SIGKDD Conference, 2023, pp. 3456-3464.
H. Wang and M. Rahman, "Intelligent resource allocation optimization for cloud computing via machine learning," arXiv Preprint, 2025.
D. Narayanan et al., "Efficient large-scale language model training on GPU clusters," arXiv Preprint, 2021.
D. Lee and H. Park, "Weighted A3C for dynamic resource scheduling in large-scale cloud environments," arXiv Preprint, 2025.
Y. Zhang and X. Wang, "Adaptive resource scheduling for edge-to-cloud deep learning systems via reinforcement learning," Future Generation Computer Systems, vol. 140, pp. 21-34, 2025.

Downloads
Published
Submitted
Revised
Accepted
Issue
Section
License
Copyright (c) 2025 Mohammad Hadi Dadizadeh Dargiry (Author)

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.









